Belajar Cross Validation Dengan Python
Masalah:
Nyari hyperparameter yang paling optimal agak susah karena data yang terbatas dan ada kemungkinan untuk mengalami overfitting kalo cuma di test dengan data tersebut.
Solusi:
Bisa coba cross validation.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn import svm
cancer_data = datasets.load_breast_cancer()
X = cancer_data.data
y = cancer_data.target
X.shape
(569, 30)
Setelah download data yang diperluin, kita bisa bagi data nya jadi training dan test data.
Pembagiannya bisa dengan gampang berkat train_test_split(),
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=9)
X_train.shape, X_test.shape
((398, 30), (171, 30))
Setelah dibagi, train data jadi ada sekitar 400 baris. Dan test data jadi sekitar 170 baris atau sekitar 30% dari total data yang ada.
Sekarang kita mau klasifikasi dengan algoritma linear support vector machine (SVM). Di dalam algoritma ini ada konfigurasi yang bisa kita atur yaitu nilai C atau regularization value. Nilai ini simpelnya bakal berpengaruh dengan seberapa fleksibel model machine learning dengan penalti untuk klasifikasi yang salah. Semakin tinggi nilai C, makin besar kemungkinan untuk overfitting. Tapi kalau terlalu kecil, ada kemungkinan untuk underfitting.
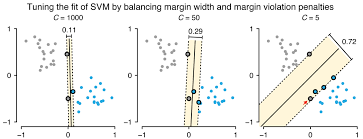
sumber: https://editor.analyticsvidhya.com/uploads/94201C.png
Misalkan kita punya 2 pilihan untuk nilai C di algoritma SVM untuk kasus ini.
Kalo tanpa cross validation biasanya kita bakal pakai test data untuk nyari nilai C dengan performa terbaik.
clf_c1 = svm.SVC(kernel='linear', C=1, random_state=9)
clf_c1.fit(X_train, y_train)
clf_c1.score(X_test, y_test)
0.9590643274853801
clf_c2 = svm.SVC(kernel='linear', C=2, random_state=9)
clf_c2.fit(X_train, y_train)
clf_c2.score(X_test, y_test)
0.9649122807017544
Sekilas bakal keliatan C=2 punya performa lebih optimal. Tapi masalahnya, performa ini cuma berlaku untuk satu set data X_train.
Bakal lebih bagus kalo ada cara untuk tes dengan data yang lebih banyak, tapi cuma pake training data yang ada. Di sinilah cross-validation bisa berguna.

sumber: https://scikit-learn.org/stable/_images/grid_search_cross_validation.png
Training data akan dibagi jadi beberapa bagian (tergantung parameter cv). Bagian-bagian ini bakal dipake untuk ngitung skor performa model yang ada.
Dengan bantuan Scikit-Learn, implementasinya sangat gampang:
scores = cross_val_score(clf_c1, X_train, y_train, cv=5, n_jobs=-1)
np.mean(scores)
0.9546518987341773
Beberapa variable penting di sini adalah:
cv: berapa jumlah bagian/foldn_jobs: jumlah cpu yang dipakai, -1 artinya pake semua biar lebih cepat! 🚀
Variabel scores adalah array yang berisi skor dari hasil validasi di tiap bagian. Kita bisa cari rata-rata nya dengan gampang berkat metode np.mean(scores).
Sekarang kita coba bandingin dengan performa kalo C=2.
scores = cross_val_score(clf_c2, X_train, y_train, cv=5, n_jobs=-1)
np.mean(scores)
0.9471518987341773
Bisa kita liat performanya lebih rendah dibanding C=1.
Jadi yang tadi kalo cuma pake test data C=2 keliatan lebih bagus, setelah di tes dengan data yang lebih bervariasi ternyata C=1 lebih pas di kasus ini.
Semoga bermanfaat!